Welcome to the weekly edition of AI Tidbits, where I curate the firehose of AI research papers and tools every week so you won’t have to.
📩 Published a new breakthrough paper? Just released an open-source package? Submit it here to ensure we don’t miss it and that it gets featured in next week’s post.
Overview
Meta AI presents MovieGen - a next-gen model family that generates HD personalized videos and synchronized audio from text prompts, enabling users to create and edit videos featuring their own faces
OpenAI introduces Canvas - a visual interface that simplifies real-time edits on writing and coding tasks within ChatGPT
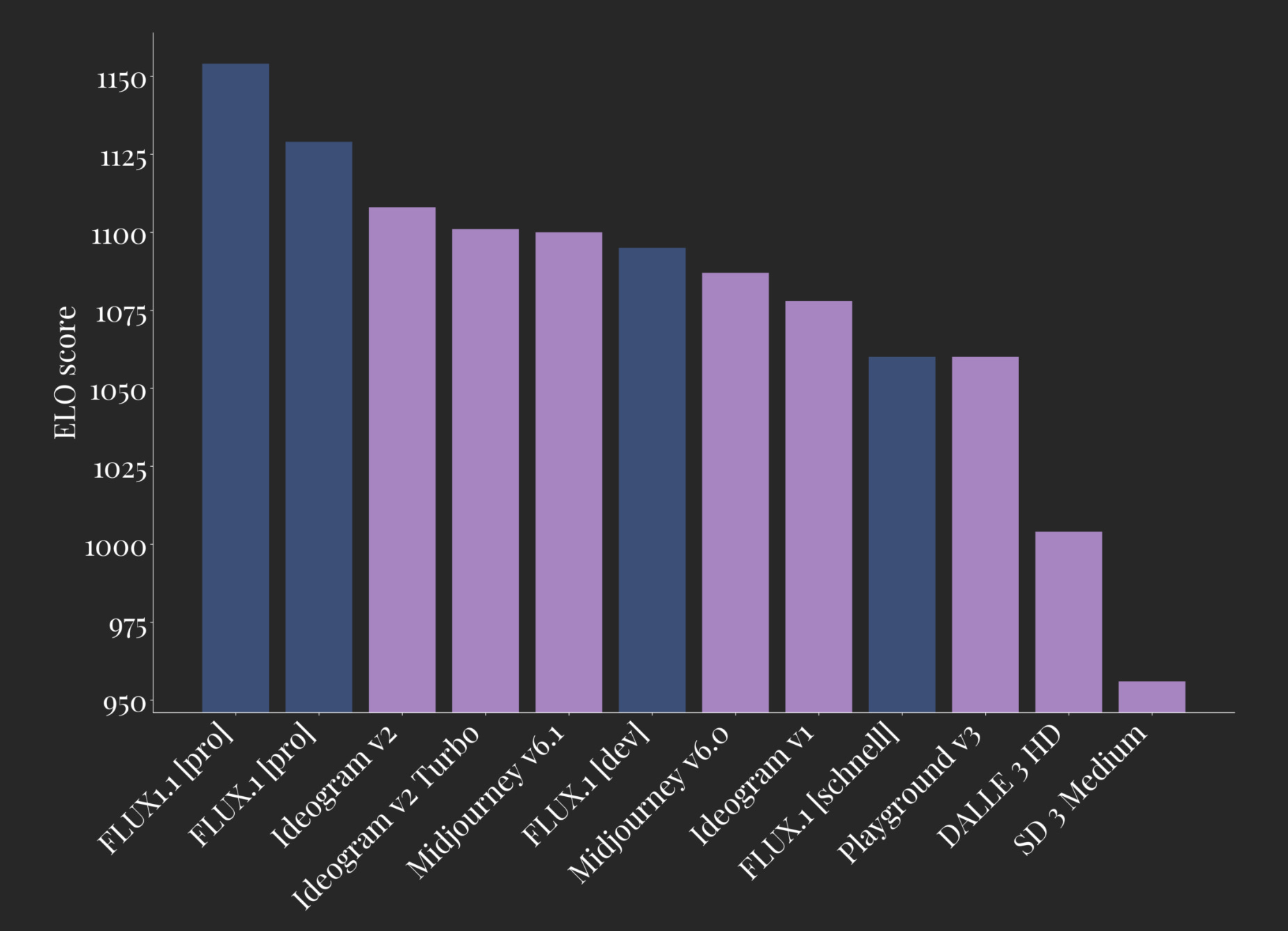
Black Forest Labs unveils Flux 1.1 Pro - a new version of its state-of-the-art text2image model, six times faster and more accurate than its predecessor, outperforming competitors like Ideogram and Midjourney in speed and prompt compliance, with API access for developers
⭐️ Exciting news - Deepgram and Writer.com join AI Tidbits credits program!
AI Tidbits premium members recieve $100 in Writer credis to build LLM-powered apps with RAG tools, AI guardrails, and more, along with $200 in Deepgram credits to build real-time voice agents.
Premium members also get full access to AI Tidbits content and $800+ for other leading AI tools and APIs, including Claude and Hugging Face.
We will be announcing more partners soon. Stay tuned.Support AI Tidbits as a premium member
A new leaderboard evaluates financial LLMs on key industry tasks like stock forecasting and credit risk scoring, offering a transparent tool for finance professionals
Cornell proposes new methods for contextualized document embeddings that incorporate neighboring documents, achieving state-of-the-art performance on the MTEB benchmark without complex training techniques
Microsoft presents Diff Transformer - a new architecture that refines attention mechanisms to outperform standard Transformers in practical applications like hallucination mitigation, long-context modeling, and in-context learning
Researchers present L-Mul – an efficient multiplication algorithm using integer additions, reducing energy costs by up to 95% for tensor operations while delivering higher precision than 8-bit floating point multiplications
Researchers present RATIONALYST – a fine-tuned LLaMa-3-8B reasoning model that outperforms larger models like GPT-4, demonstrating superior reasoning across diverse tasks by leveraging 79k rationale annotations for more explicit reasoning
Mila, DeepMind, and Microsoft reveal gaps in reasoning abilities of smaller AI models like Phi-2 and Mistral 7B, raising concerns about their limitations in handling complex problems
The PyTorch team releases torchao - a new library that speeds up model inference by up to 97% with advanced quantization and sparsity techniques
Technion and Google demonstrate that LLMs encode truthfulness in specific tokens, enhancing error detection while also predicting error types and uncovering a mismatch between internal truth encoding and external behavior
Stanford showcases Tutor CoPilot - a Human-AI system that provides expert-like guidance to tutors, leading to a 9% improvement for students of lower-rated tutors
Cohere releases upgraded Command R and R+ models, improving efficiency and lowering API costs for enterprise RAG tasks
Researchers present Leopard – a multimodal LLM tailored for multi-image, text-rich tasks, using a specialized high-resolution encoding module and 1M instruction-tuning data to achieve superior benchmark performance
ByteDance and University of Maryland develop LLaVA-Critic – an open-source large multimodal model for multimodal tasks evaluation, outperforming GPT models on multiple benchmarks and enhancing model alignment via preference learning
Apple presents a novel captioning pipeline that enhances multimodal model pre-training by combining synthetic captions and AltTexts, improving performance and alignment across models like CLIP and diffusion models
Apple fully open-sources Depth Pro - a fast and efficient foundation model that delivers high-resolution, metric monocular depth estimation without camera metadata, achieving superior sharpness and boundary accuracy
UHK and ByteDance introduce Loong - a novel autoregressive LLM-based video generator that produces minute-long videos by addressing challenges in long video training and inference
KAIST publishes VideoGuide - a framework that enhances temporal consistency in text-to-video generation without retraining, by integrating denoised samples from pretrained models during inference
Tsinghua University develops SageAttention – a quantization method that boosts attention performance by up to 2.7x OPS while maintaining superior accuracy over FlashAttention3
UCSD and Adobe introduce Presto! - an efficient text-to-music generation method, combining step and layer distillation to achieve 10-18x acceleration and best-in-class performance for diverse, high-quality outputs
An international team of researchers releases MOSEL - an open-source speech dataset with ~950k hours of transcribed data across 24 EU languages
Expression Editor - edit face expressions in any image
OpenMusic - turn text into music
Alter faces using Expression Editor GPT Pilot - AI writes 95% of the code for an app, and human engineer pulled by the AI for the remaining 5%
LightLLM - LLM inference and serving framework, notable for its lightweight design, easy scalability, and high-speed performance
DepthFlow - turn images into short effect videos
Podcastfy - transforming text into captivating multilingual audio conversations with AI
Plus >70 more open-source packages for AI engineers
Last week’s AI Tidbits roundup
Reach AI builders, researchers, and entrepreneurs by partnering with AI Tidbits
If you find AI Tidbits valuable, share it with a friend and consider showing your support.


![AQOvFTvzMc4bgV0UnKk434s09calfDp_gjzyUeu1PT9805-esb4Ri0sObRJ-KI7JmOlqkTI-Q9jpRLi_oZufrdgL.mp4 [optimize output image]](https://substackcdn.com/image/fetch/$s_!n7rW!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fbe6d1753-7e55-4c2c-931e-2667dcba7316_800x450.gif "AQOvFTvzMc4bgV0UnKk434s09calfDp_gjzyUeu1PT9805-esb4Ri0sObRJ-KI7JmOlqkTI-Q9jpRLi_oZufrdgL.mp4 [optimize output image]")
![temp.mov [optimize output image]](https://substackcdn.com/image/fetch/$s_!ezdO!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F3be6b81d-ce91-4216-8538-090b637a0860_800x450.gif "temp.mov [optimize output image]")











![koala_12s.mp4 [optimize output image]](https://substackcdn.com/image/fetch/$s_!Z-kq!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fcf4b822e-e357-4515-a987-cb9d237073c7_600x600.gif "koala_12s.mp4 [optimize output image]")
![temp.mov [optimize output image]](https://substackcdn.com/image/fetch/$s_!IYna!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fe756ad41-d26a-4128-b9e3-a260cac85a34_600x231.gif "temp.mov [optimize output image]")


![338362925-aac0b531-83e4-4847-98d8-25d396dfec17.mp4 [optimize output image]](https://substackcdn.com/image/fetch/$s_!4V8g!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F0ef01843-f35c-4141-8a31-df8d7d881c8b_600x338.gif "338362925-aac0b531-83e4-4847-98d8-25d396dfec17.mp4 [optimize output image]")

That Expression Editor is quite fun, and uncannily consistent. Impressive how it can affect the facial expression without creating any odd artifacts in the rest of the image.