
Top 8 leaderboards to choose the right AI model for your task
A comprehensive guide to help AI developers and researchers find the most efficient, accurate, and cost-effective language models for their projects

Welcome to a new post in the AI Builders Series - helping AI developers and researchers study and deploy the latest breakthroughs reliably and efficiently.
A NotebookLM-powered podcast episode discussing this post:
Me: What language model do you use for your [enter task name here]?
AI peer: GPT-4
Me: Why? I bet a smaller model will work while being cheaper and faster
AI peer: I don’t know. I didn’t know what to choose and that was the safest bet
Me: let me write that blog post
Blog post:
The space of generative AI is moving fast across modalities. From language and text to image and video. In 2023 alone, we saw the state-of-the-art (SOTA) language model, GPT, grow from a context window of 4k to 128k, with a remarkable boost in performance: +16% and +18% on MMLU and HumanEval, respectively.
Additionally, the year was marked by the release of hundreds of capable open-source models. In March 2023, we celebrated each new model with a special announcement: from Dolly to MPT and Vicuna. These days, a new SOTA model comes out every other day.
So it is hard to stay up to date. It is hard to know which model to choose for your language model-powered app. Luckily enough, a few leaderboards were introduced in the last few months that make this task a tad easier.
By ranking models based on their efficiency, accuracy, and other metrics, leaderboards provide a clear, comparative snapshot of their capabilities. These then become a valuable resource for identifying which models are leading the pack in any given domain, from understanding human language to recognizing objects in images.
This post, the fourth in a series, aims to guide developers and researchers in choosing the right language model for their tasks, ensuring they launch accurate, efficient, and cost-effective LLM applications.

General guidelines for choosing models
Everyone wants to use the best available model. The thing is, ‘best’ is subjective according to your task. More often than not, a state-of-the-art proprietary model like GPT-4 would be an overkill for a simple summarization task, like using a sledgehammer to crack a nut.
Determining the ideal model for your needs requires evaluating models’ performance, type, latency, and cost.
Performance Metrics
Language model leaderboards feature various metrics like ARC, HellaSwag, MMLU, and GSM8K. These are benchmarks that were created in academia to assess language models’ capabilities:
Multitask Multidomain Language Understanding (MMLU) - this benchmark offers a thorough evaluation of text models' knowledge spanning 57 diverse subjects, including humanities, social sciences, STEM, and beyond. It serves to identify knowledge gaps and limitations in large language models.
AI2 Reasoning Challenge (ARC) - ARC assesses models' capacity for answering complex questions that require deeper knowledge and reasoning beyond mere retrieval. With around 7.5k questions from grade-school science, it pushes for advancements in AI by demanding reasoning, commonsense, and in-depth text understanding.
HellaSwag - HellaSwag evaluates commonsense in AI, particularly in completing sentences and paragraphs in a way that makes sense. A question in the HellaSwag dataset typically involves presenting a scenario with multiple-choice answers for how it could logically continue. For example, "A chef opens a refrigerator, looking for ingredients. What is the most plausible next action? A) chef selects vegetables, B) chef reads a newspaper, C) chef flies away with a jetpack, D) chef plays a guitar.”
TruthfulQA - created to gauge language models' accuracy in answering a broad range of questions, this benchmark encompasses 817 questions across 38 categories, focusing on misleading responses mirroring common misconceptions in training data. It aims to measure the propensity of models to generate incorrect or misleading information without specific task tuning.
When evaluating leaderboards, prioritize benchmarks relevant to your project's requirements. For instance, if your app requires strong reasoning skills for intricate question-answering challenges, consider models that excel in the ARC dataset. To gauge a model's tendency for generating inaccurate information, scrutinize its performance on TruthfulQA or MMLU. For insights into a model's ability to apply commonsense reasoning, HellaSwag scores can be particularly telling. A higher score on these benchmarks typically indicates superior performance in the respective areas.
Model Types
There are different kinds of models: pretrained, fine-tuned on domain-specific datasets, MoE (Mixture of Experts), and chat models. If you are looking for a model that can be immediately integrated without additional training, a pretrained model like Llama 2 will be suitable. However, if your task is very specific, a model fine-tuned on your relevant dataset could perform better.
Latency and cost
Smaller models are cheaper to host and provide faster inference. Larger models generally have higher capacity for complex tasks but are slower and more expensive to host.
A small 1.5B parameters model like Stable LM would yield dozens of tokens per second on an Nvidia A100 or even a local Mac machine, while a Qwen 72b would struggle to fit to memory and be substantially slower. Depending on your computational budget and the complexity of the task, you might choose a smaller or larger model.
Precision types like float16, bfloat16, 8bit, 4bit, and GPTQ also impact the computational efficiency of the model. Lower precision models like 8bit or 4bit may be faster and use less memory, making them suitable for deployment in environments with limited resources.
Choosing the right model is just one way to reduce latency and cost. Explore 11 other techniques in this AI Tidbits deep dive:

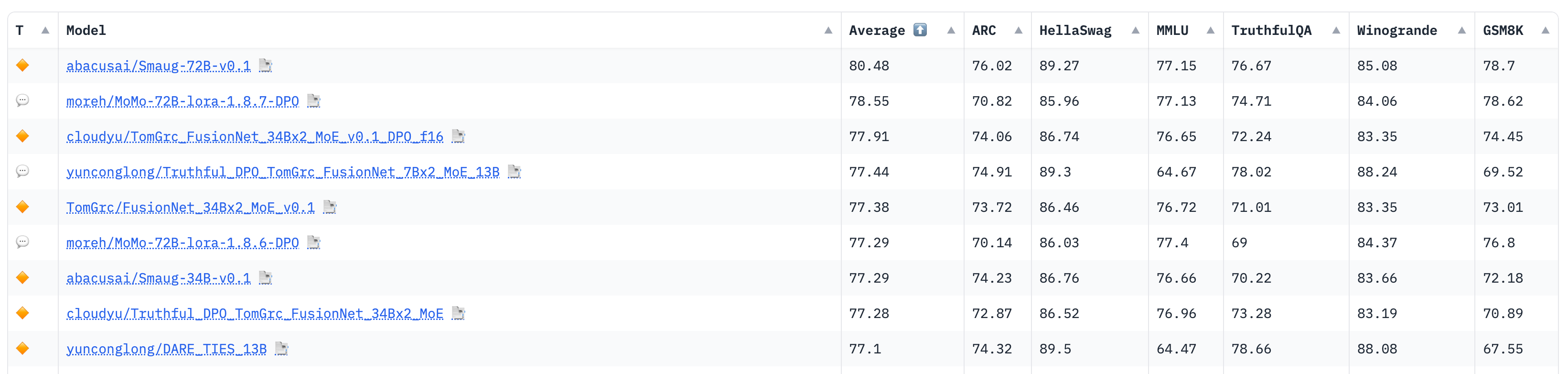
Open LLM Leaderboard
Hugging Face’s Open LLM Leaderboard is one of the most popular leaderboards. It ranks open-source language models, including Mixtral and Yi, as well as newcomers like Smaug and Qwen, across a spectrum of benchmarks, model types, and model sizes. It doesn’t, however, feature proprietary models like Gemini and GPT.
For an AI developer looking at the Open-source LLM dashboard, my advice would be:
Define the criteria that are most important for your use case, such as specific task performance, computational efficiency, or versatility
Use the filtering options to narrow down the models that excel in the benchmarks relevant to your task
Consider the trade-offs between model size and precision in the context of where the model will be deployed. Faster, less capable, smaller language models vs. larger ones.
Look for models that have been fine-tuned on datasets that are close to your application’s domain for better performance
Check the licensing and availability of the models on the Hugging Face Model Hub, as this will affect how you can use them. A non-commercially permissive model cannot be used if you’re turning any revenues.
By now, this leaderboard features thousands of models, making it a challenge to navigate. While filtering aids in narrowing the options, the sheer volume can still be overwhelming. These days, I leverage this leaderboard as a discovery tool, uncovering new SOTA models and then exploring them by clicking on their names to access their detailed Hugging Face model cards.
Become a premium to access the LLM Builders series, $1k in free credits for leading AI tools and APIs, and editorial deep dives into key topics like OpenAI's DevDay and autonomous agents.
Many readers expense the paid membership from their learning and development education stipend.Hallucinations Leaderboard
Keep reading with a 7-day free trial
Subscribe to AI Tidbits to keep reading this post and get 7 days of free access to the full post archives.