
12 techniques to reduce your LLM API bill and launch blazingly fast products
Reducing your LLM API bill and latency by order of magnitude through research-backed and hard-learned lessons

Welcome to Deep Dives - an AI Tidbits section providing editorial takes and insights to make sense of the latest in AI.
A NotebookLM-powered podcast episode discussing this post:
While launching user-facing ML-powered applications has been around for more than a decade now, open-ended language models have only surged in popularity in the last 12 months. Given this nascency, best practices for managing cost, latency, and accuracy in LLM-powered applications are still being developed.
Minimal latency is crucial for developers building user-facing applications, as users get frustrated when waiting for something to happen. Cost is another critical metric. LLM applications must be financially viable–generative AI startups charging users $9/month would find a $20/month LLM API cost per user unsustainable.
Lowering latency and cost tends to go hand in hand - shortening prompts, caching responses, using cheaper models, and other techniques I outline in this post lead to cheaper and faster generations.
2024 has been marked as the year in which LLM apps graduate from mere prototypes to production-ready scalable applications. This is the second piece in a series packed with hands-on tips and research-backed learnings drawn from my experience and the expertise of fellow builders.
Combined with my previous article on prompting techniques to minimize hallucinations, this series will help you launch LLM applications that are accurate, efficient, and cost-effective.
Let's dive into the first of twelve methods.

Semantic Caching
At a recent LLM developers conference, I was surprised to discover that numerous developers still don't utilize caching for LLM responses, resulting in unnecessary increased costs and latency.
Caching, in the context of language models, is storing prompts and their corresponding responses in a database for future use. By caching responses to previously posed questions, LLM-powered apps can deliver faster and cheaper responses, eliminating the need for repetitive LLM API calls.
It works for an exact match, i.e., using the same prompt twice, or for a similar match, i.e., two prompts with the same meaning. For example, “Who was the first US president?” and “Tell me who was the first US president?” is not an exact match but would yield the same answer, therefore saving an API call.

GPTCache is a great start and only requires a few lines of code. It also provides metrics such as the cache hit ratio, latency, and recall to gauge how well your cache performs and improve it. Here is a brief example from the docs:
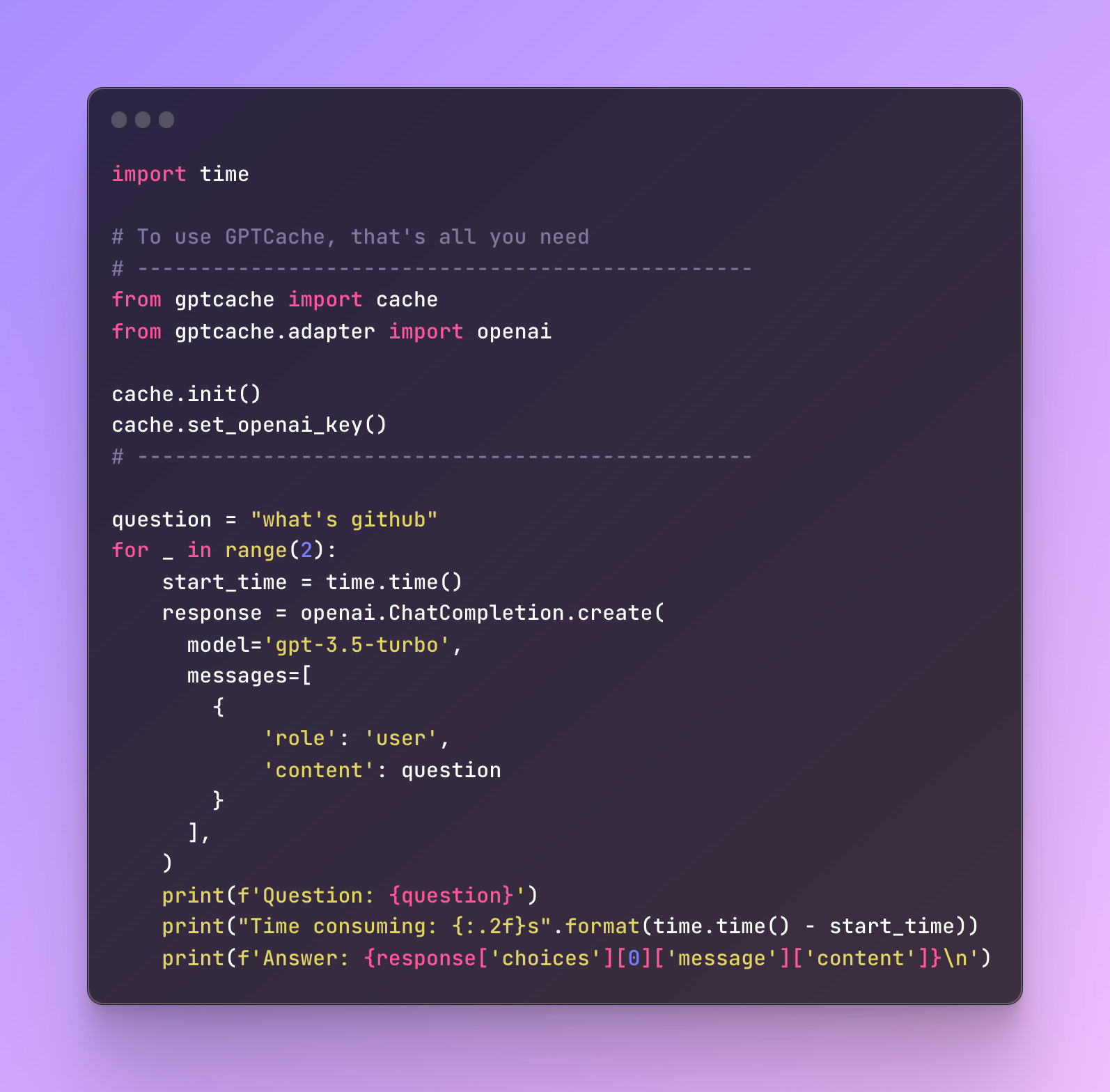
The benefits of caching are:
Faster and cheaper inference in production, with some queries achieving close-to-zero latency thanks to a cached response
Faster and cheaper development cycles, as you don’t incur costs or wait for the response when working with the same prompt repeatedly
Having all prompts stored in a database simplifies the process of fine-tuning a language model once you choose to do so, as you can use the stored prompt-response pairs
Make sure to refresh the cache once in a while or when content changes (e.g. support docs) to prevent outdated wrong responses.
Summarizing lengthy conversations
Imagine creating an AI to handle your phone calls. Each time the human agent responds, their reply and the AI's generated response are added to the conversation, accumulating words, and hence tokens, in the process. Consequently, a short two-minute call can result in a 300-word dialogue.

Such long multi-turn conversations can be summarized once every few turns to remove redundant text, the kinds of “Hello, how can I help?” and “Let me check with my supervisor”.
You can manually summarize or use an existing package like LangChain’s ConversationSummaryMemory. This type of memory creates a summary of the conversation over time. This memory can then be used to inject the conversation summary into a prompt or chain.
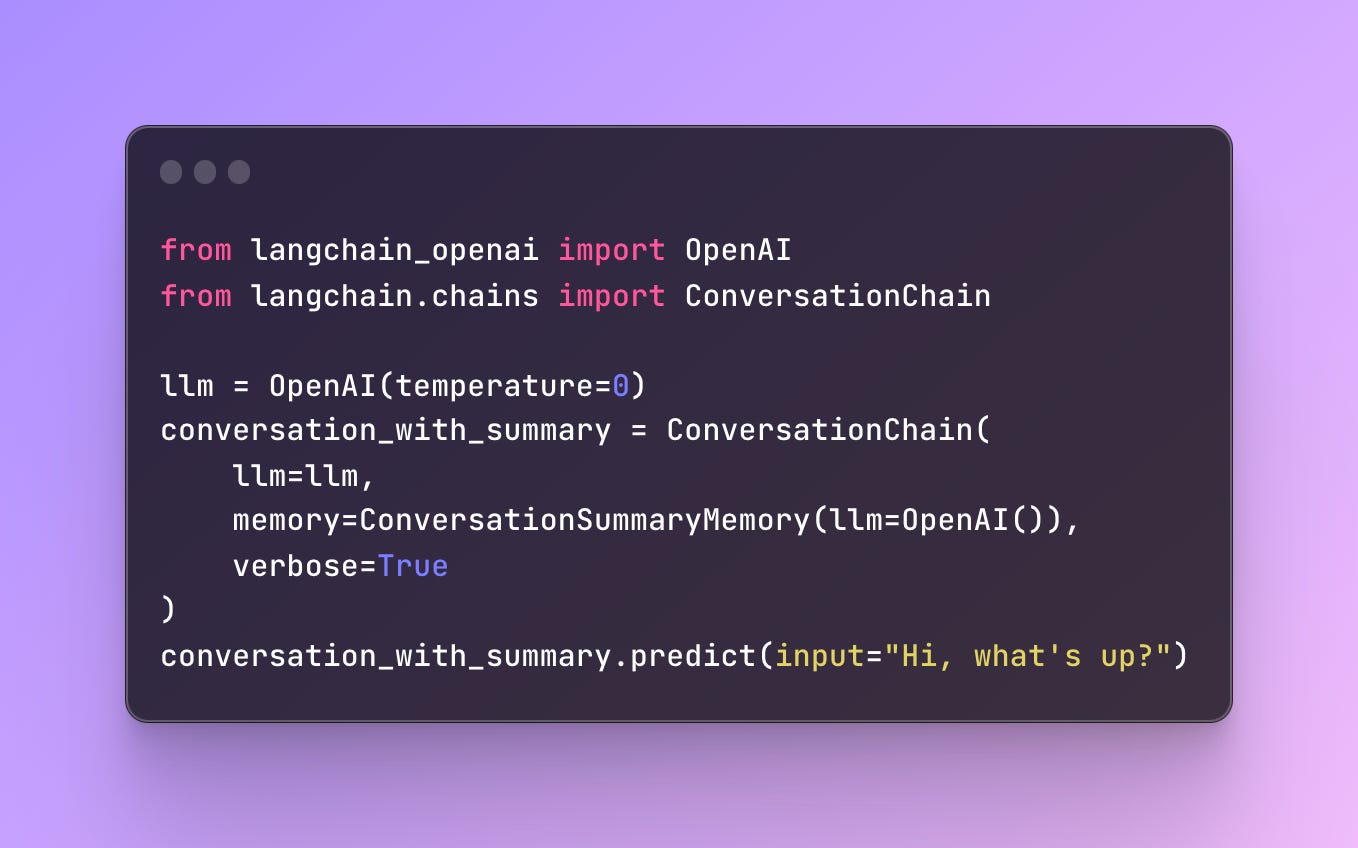
Based on my experience, I’d recommend using GPT-3 Turbo as the summarization LLM. It is cheaper, faster, and performs well. ConversationBufferWindowMemory is another flavor that only keeps the last X number of interactions, avoiding an ever-growing history of messages.
Summarization saves you tokens and reduces latency by condensing the prompt, keeping the most essential context while removing the fluffy parts.
Become a premium to access the LLM Builders series, $1k in free credits for leading AI tools and APIs, and editorial deep dives into key topics like OpenAI's DevDay and autonomous agents.
Many readers expense the paid membership from their learning and development education stipend.Compressing prompts
Recent trends such as longer context windows, advanced prompting techniques (e.g. Chain-of-Thought), and Retrieval Augmented Generation result in lengthy prompts. Lengthy prompts lead to slow and expensive LLM API calls and inferior performance due to issues such as “lost in the middle”, which is when language models ignore relevant information due to excessively long prompts.
Keep reading with a 7-day free trial
Subscribe to AI Tidbits to keep reading this post and get 7 days of free access to the full post archives.